CH11: Recovery & Post-Incident Activity
Introduction
The environment is clean. The attacker's malware is removed, their persistence mechanisms are documented and deleted, their stolen credentials are rotated, and the verification checks from Chapter 10 have returned clean results. The Incident Commander has signed off on eradication.
But the organization is still operating in a degraded state. Systems are offline or isolated. Users are displaced to temporary workarounds. Business processes that depend on the affected infrastructure are running manually, or not running at all. Leadership is asking the same question from a different angle: not "When can we go back to normal?" but "In what order do we bring things back, and how do we know they're safe?"
Recovery is the phased, prioritized process of restoring business operations to their pre-incident state, or ideally, to a stronger state than before. It is not a single switch-flip. Systems must be brought online in the correct sequence, validated for both technical integrity and data accuracy, and monitored closely for any signs that the eradication was incomplete.
Post-Incident Activity is the often-neglected final phase of the IR lifecycle. It is where the organization transforms a painful experience into lasting improvement. The Post-Incident Review, the metrics, the After Action Report, and the plan updates that emerge from this phase are what separate organizations that learn from incidents from those that simply survive them.
Learning Objectives
By the end of this chapter, you will be able to:
- Design a phased recovery plan that prioritizes system restoration based on BIA criticality tiers and Critical Business Functions.
- Apply recovery validation techniques, including monitoring for residual compromise and confirming data integrity before declaring systems operational.
- Facilitate a Post-Incident Review (PIR) using blameless methodology to extract process improvements without creating a culture of fear.
- Calculate key incident response metrics (MTTD, MTTR, and dwell time) and explain their value for measuring program maturity.
- Construct an After Action Report (AAR) and a program improvement plan that feeds lessons learned back into Preparation.
11.1 Phased Recovery
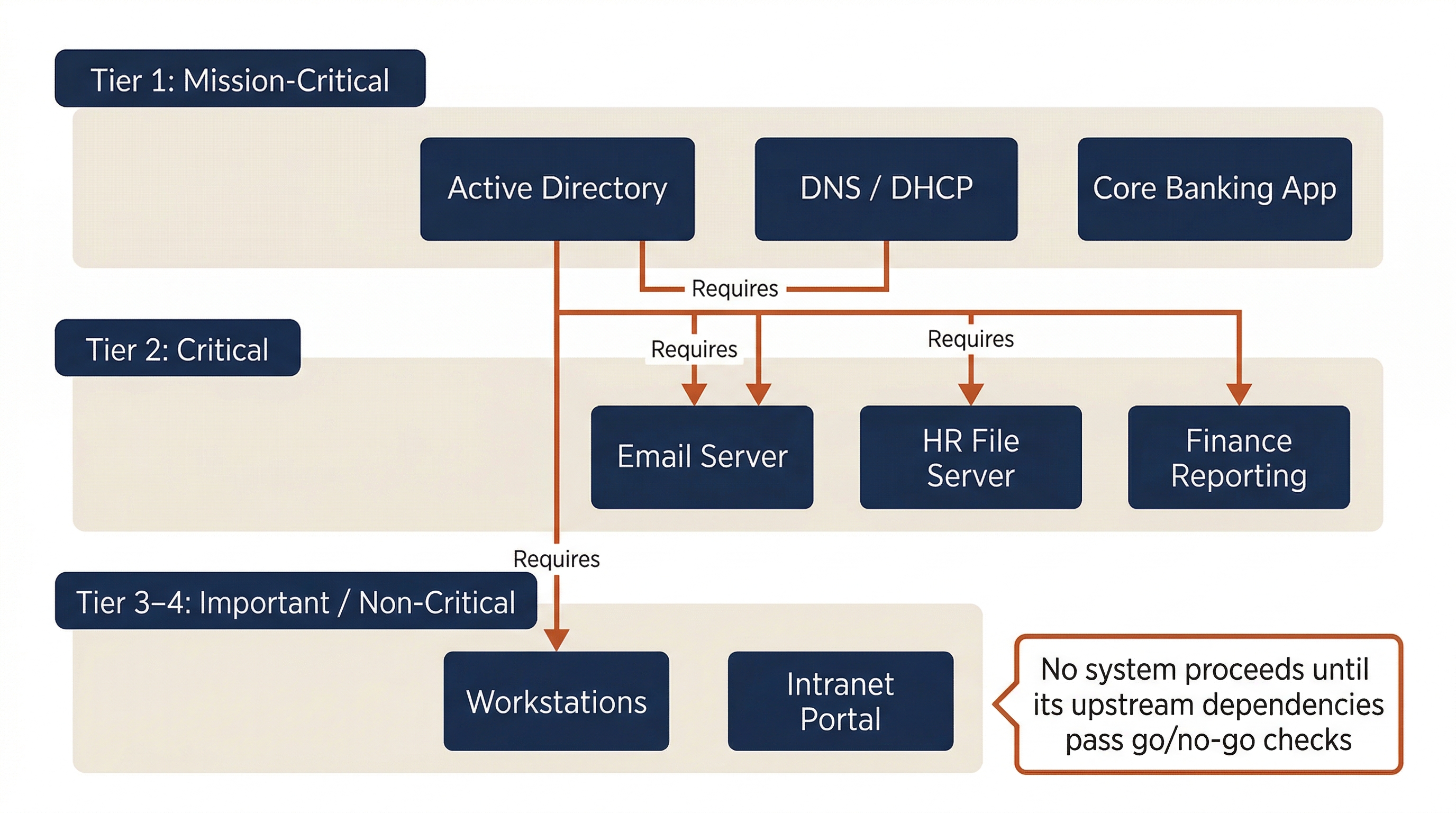
Recovery is not "restore everything at once." It is a sequenced, prioritized process driven by the Business Impact Analysis (BIA) developed in Chapter 2. The BIA identified which business functions are Mission-Critical, which are Critical, which are Important, and which are Non-Critical. Those tiers now dictate the recovery order.
Restoration Priority
The BIA's Critical Business Functions (CBFs) and their associated Recovery Time Objectives (RTOs) determine which systems come back first. Chapter 2 established four criticality tiers:
| Recovery Order | BIA Tier | RTO Target | Examples (Meridian Financial) |
|---|---|---|---|
| First | Tier 1: Mission-Critical | < 4 Hours | Active Directory (DC-01, DC-03), Core banking application, DNS/DHCP |
| Second | Tier 2: Critical | 24 Hours | Email, HR file server (FS-HR-01), Finance reporting application |
| Third | Tier 3: Important | 72 Hours | Intranet portal, vendor invoicing system |
| Fourth | Tier 4: Non-Critical | > 1 Week | Training portal, archival storage, employee wellness app |
Recovery Sequencing and Dependencies
Criticality tiers alone do not determine the sequence. Dependencies matter. A Tier 2 system cannot come online if the Tier 1 infrastructure it relies on is not restored first.
Chapter 2 introduced upstream and downstream dependency mapping. During recovery, those dependency maps become operational checklists:
- Active Directory must be online before any domain-joined system can authenticate. It is the foundation; nothing else works without it.
- DNS and DHCP must be functional before workstations can resolve names and obtain addresses.
- The email server depends on AD for authentication, DNS for mail routing, and the firewall for external connectivity.
Each system in the recovery queue has a go/no-go gate, a set of prerequisites that must be confirmed before it is reconnected to production. If the prerequisites are not met, the system waits.
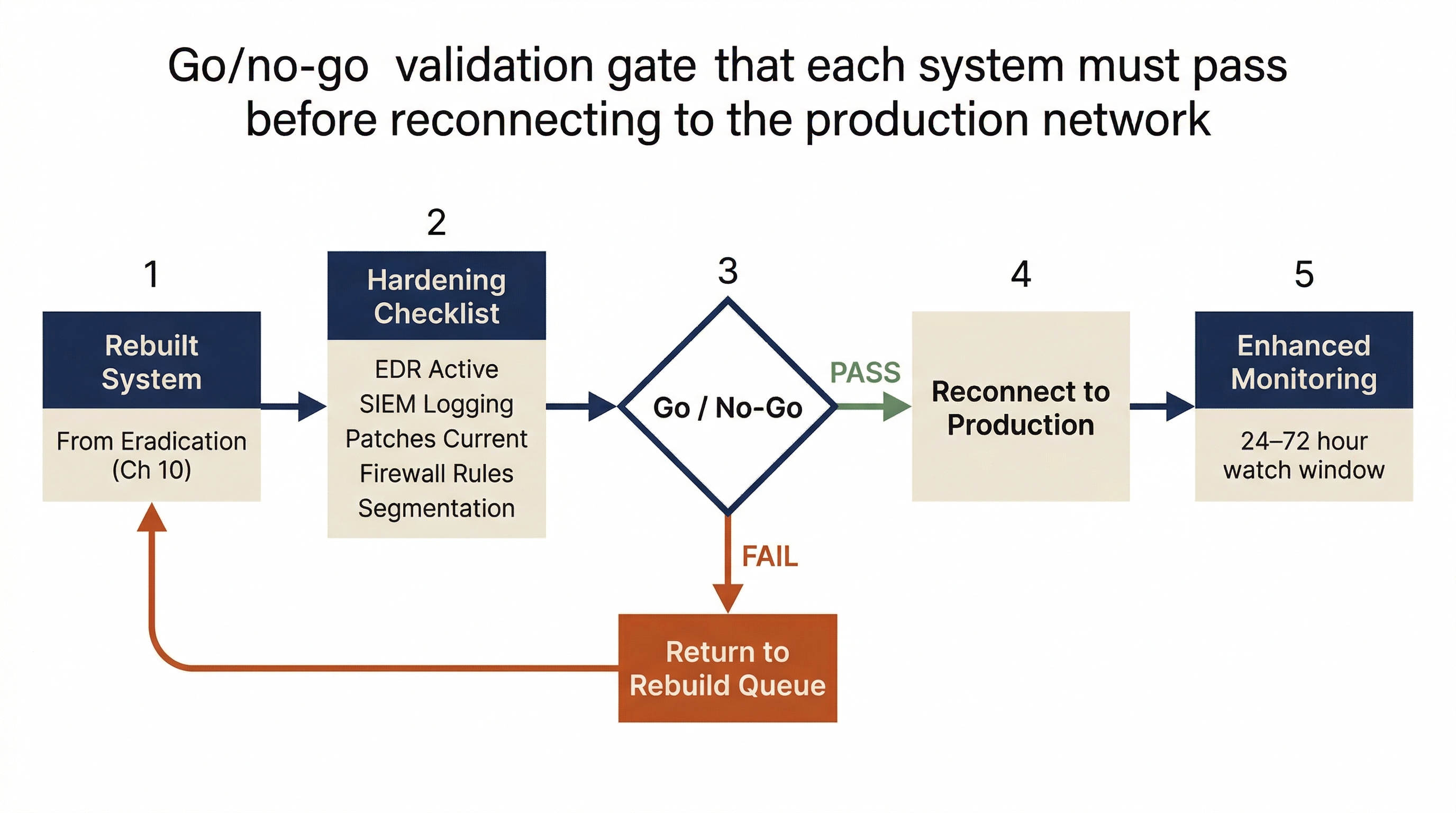
Hardening Before Reconnect
Chapter 10 rebuilt compromised systems to hardened baselines. Before reconnecting those systems to the production network, the team must confirm:
- EDR agent is installed, active, and reporting current telemetry.
- Logging is configured and flowing to the SIEM.
- Host-based firewall rules match the hardened baseline.
- The system's patches are current (not restored from a pre-incident backup that reintroduces old vulnerabilities).
- Any new segmentation rules from the remediation plan are active.
A system that passes these checks is cleared for reconnection. A system that fails any check goes back to the rebuild queue.
Monitoring During Startup
Recovery is a high-risk window. If any trace of the attacker was missed during eradication, reconnecting systems to the network will reactivate it. Enhanced monitoring is not optional during this phase. It is the safety net.
Warning
Recovery Is a High-Risk Window
The period immediately after systems are reconnected is when missed persistence mechanisms or undiscovered compromises reveal themselves. The SOC must be running real-time monitoring with heightened sensitivity during recovery. Specifically, watch for: C2 beacon attempts from recovered systems (check the sinkhole logs), unexpected outbound connections, unauthorized process execution, and authentication anomalies. If any of these indicators appear, halt recovery on that system and loop back to Analysis (Chapter 8).
11.2 Recovery Acceptance and Data Integrity
Bringing a system online is not the same as declaring it recovered. Recovery acceptance is the formal process of confirming that a restored system meets both technical and business requirements before it is handed back to operations.
Recovery Acceptance Criteria
A system is accepted as recovered when all of the following conditions are met:
- Service health checks pass: The application responds to requests, endpoints connect, and dependent services function correctly.
- Security controls verified active: EDR reporting, log flow to SIEM, MFA enforced, segmentation rules in place.
- Monitoring window clear: A defined observation period (typically 24-72 hours) has elapsed with no anomalous activity detected.
- Business owner sign-off: The functional owner of the system (e.g., the Finance Director for the reporting application) confirms the system is operating correctly and the data is accurate.
No system transitions from "recovered" to "operational" without both the technical team and the business owner signing off. This dual validation prevents the scenario where IT declares victory but the application is returning incorrect data.
Data Integrity Validation
Restored data must be verified before business processes rely on it. This is especially critical in ransomware incidents where data is restored from backups, and the backup itself may be older than expected, partially corrupted, or missing recent transactions.
Data integrity validation operates on two levels:
Technical validation confirms the data is structurally sound:
- Hash comparisons between restored files and known-good references (where available).
- Database consistency checks (DBCC CHECKDB for SQL Server, pg_dump verification for PostgreSQL).
- Backup integrity verification: confirming the restore completed without errors and the backup chain is unbroken.
Business validation confirms the data is functionally correct:
- End users verify that restored records match their expectations. ("Does the payroll data for last period match? Are all 2,000 employee records present? Do the account balances reconcile?")
- Spot-check critical transactions that occurred near the incident window.
- Verify that any data entered manually during the outage (the Work Recovery Time from Chapter 2) has been integrated correctly.
Analyst Perspective
In ransomware recovery, the question is not just "Did the backup restore successfully?" but "How old is this backup?" If the RPO was 24 hours and the last clean backup is 72 hours old, the business has lost three days of data, not one. That gap must be communicated to the business owner immediately, and a plan must be developed to reconstruct the lost transactions. Surprises during recovery acceptance are far worse than honest communication up front.
11.3 The Post-Incident Review
The Post-Incident Review (PIR), also called "Lessons Learned" or a "Hot Wash," is arguably the most valuable phase of the entire IR lifecycle. It is also the most frequently skipped. Organizations exhausted from the incident want to move on. Leadership considers the crisis resolved. The IR team is behind on their normal workload.
Skipping the PIR guarantees that the same failures will recur. Every incident contains intelligence about what broke, what worked, and what needs to change. The PIR is the mechanism for capturing that intelligence before it fades.
Timing and Participants
The PIR should be conducted within 1-2 weeks of incident closure, while memory is fresh. Waiting longer than two weeks significantly degrades recall and reduces the urgency to act on findings.
The participant list should include everyone who played a role:
- SOC analysts and the Incident Commander
- IT Operations staff who executed recovery actions
- Legal Counsel (especially if breach notification was involved)
- HR (if the incident involved insider threat or employee impact)
- Public Relations (if external communications were issued)
- Business owners of affected systems
- Third-party responders (if external IR firms were engaged)
The Blameless Methodology
The single most important principle of the PIR is that it focuses on process failures, not individual failures. This distinction is the difference between an organization that learns and one that punishes.
Consider the difference:
- Blame-focused: "The analyst didn't escalate fast enough, which allowed the attacker to spread."
- Blameless: "The escalation criteria in the IR Plan were ambiguous for this scenario. The analyst followed the documented process, but the process did not account for lateral movement indicators. The IR Plan needs updated escalation triggers for confirmed credential theft."
The first approach teaches the team to hide mistakes. The second approach fixes the system. Both identify the same gap, but only the blameless approach leads to improvement.
If individuals fear punishment, they will underreport, delay escalation, and avoid documenting their actions. This makes the next incident worse, not better.

Structured PIR Agenda
A productive PIR follows a structured format. The following template provides a framework:
| Phase | Discussion Points | Output |
|---|---|---|
| Timeline Reconstruction | Walk through the incident chronologically. What happened, when, and in what order? | Validated incident timeline |
| What Went Well | Identify actions, decisions, and tools that were effective. Celebrate wins. | Practices to reinforce and repeat |
| What Could Be Improved | Identify process gaps, tool limitations, communication failures, and escalation delays. | Specific improvement recommendations |
| Root Cause Review | Revisit the RCA from Chapter 10. Were the root causes accurately identified? Are the remediations on track? | Validated or revised RCA |
| Action Items | Assign every recommendation to an owner with a due date. | Tracked improvement plan |
What Went Well: An Often-Skipped Step
Many PIRs devolve into a list of complaints. Deliberately starting with "What went well" serves two purposes. First, it sets a constructive tone. Second, it identifies effective practices that should be reinforced, not just problems to fix. If the DNS sinkhole from Chapter 9 was the action that revealed the fourth compromised host, that technique should be formalized in the playbook for future incidents.
11.4 Metrics and Reporting
Metrics transform a subjective narrative ("we responded quickly") into objective measurement ("our MTTD was 72 hours, down from 156 hours last year"). Without metrics, it is impossible to measure program maturity, justify budget requests, or demonstrate improvement over time.
Core IR Metrics
| Metric | What It Measures | How to Calculate | Industry Context |
|---|---|---|---|
| MTTD (Mean Time to Detect) | How long the attacker was present before the organization noticed | Time from initial compromise to first detection alert | Lower is better. Industry averages vary widely, from days to months depending on sector |
| MTTR (Mean Time to Respond) | How quickly the team contained the threat after detection | Time from detection to confirmed containment | Measures IR team speed and decisiveness |
| Dwell Time | Total attacker presence in the environment | Time from initial compromise to full eradication | The most comprehensive measure of overall IR program effectiveness |
| Time to Contain | Speed of the Containment phase specifically | Time from containment decision to verified containment | Identifies whether containment processes and approvals are efficient |
| Time to Recover | Duration of the Recovery phase | Time from eradication sign-off to full operational recovery | Measures DR and IT Operations efficiency |
Applying Metrics to Meridian Financial
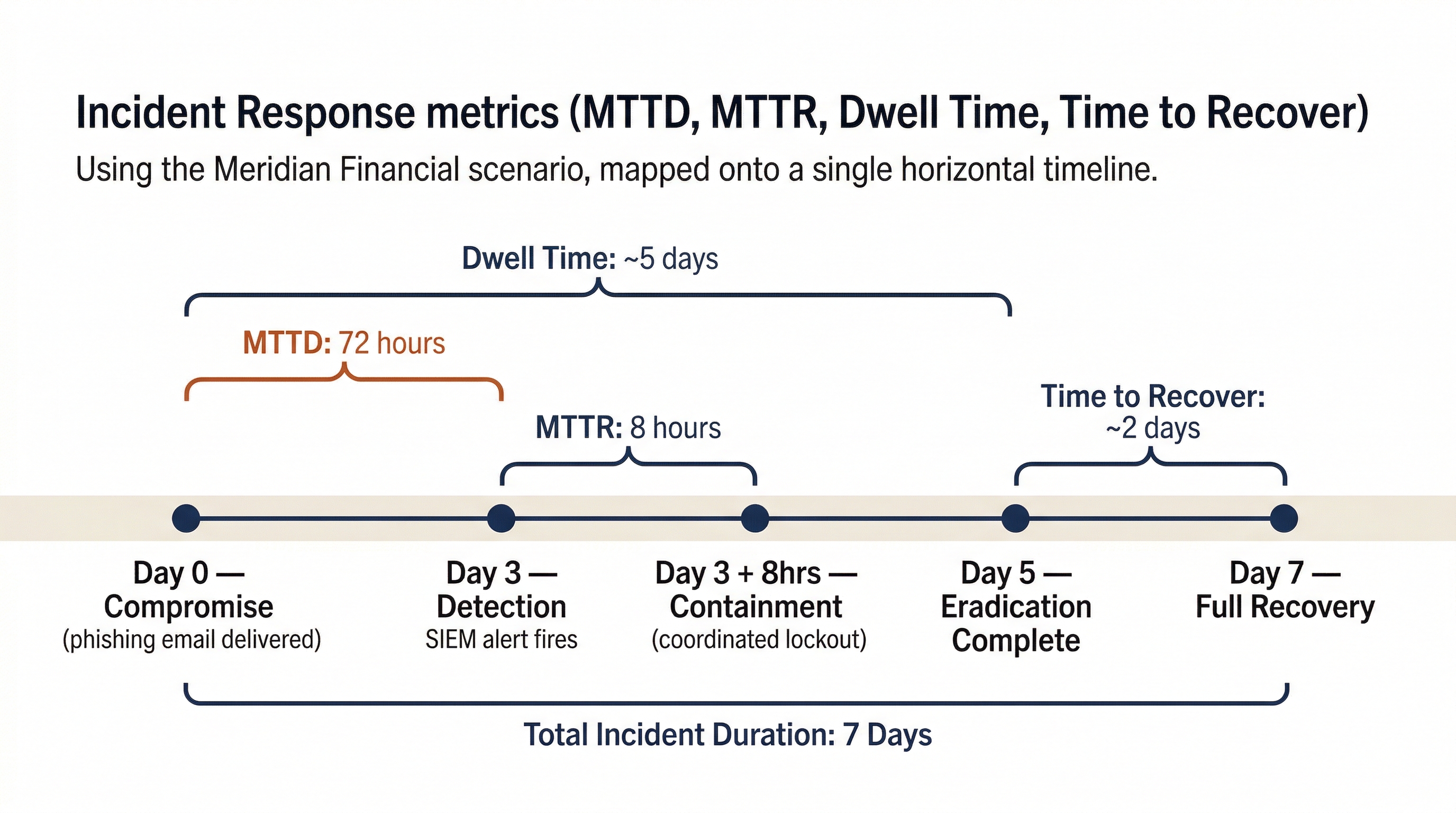
For the Meridian Financial scenario that has run through Chapters 9-11:
- Initial Compromise: Day 0 (phishing email delivered, macro executed on WS-FIN-042).
- Detection: Day 3 (SIEM alert triggered on C2 beaconing pattern).
- Containment Verified: Day 3 + 8 hours (coordinated lockout executed, containment hold begins).
- Eradication Complete: Day 5 (all systems reimaged, KRBTGT double-reset complete, rogue GPO removed).
- Recovery Complete: Day 7 (all systems restored, business validation signed off).
This yields:
- MTTD: 72 hours (3 days from compromise to detection)
- MTTR: 8 hours (detection to containment)
- Dwell Time: ~5 days (compromise to eradication complete)
- Time to Recover: ~2 days (eradication sign-off to full operations)
These numbers tell a story. The 72-hour MTTD indicates that the organization's detection capability missed three days of attacker activity. The 8-hour MTTR shows the team acted decisively once the alert fired. The improvement priority is clear: invest in detection (better SIEM rules, threat hunting, and user awareness training to shorten that 72-hour gap).
The Executive After Action Report (AAR)
The AAR is the formal written deliverable produced after the PIR. It serves two audiences: technical leadership (CISO, SOC Manager) who need operational detail, and executive leadership (CEO, Board, Legal) who need strategic context.
The AAR is not the forensic report. It is a strategic document that translates the incident into business risk language. A well-structured AAR includes:
- Executive Summary: 1-2 paragraphs summarizing the incident, its business impact, and the resolution.
- Incident Timeline: Key milestones (detection, containment, eradication, recovery) with dates and times.
- Root Cause Analysis: The findings from Chapter 10, stated in terms executives understand.
- Response Effectiveness: What worked, what did not, and where the gaps were, supported by the metrics above.
- Recommendations: Specific, prioritized actions to prevent recurrence, each tied to a finding from the incident.
- Remediation Status: The current state of the remediation tracking plan from Chapter 10, including what is complete, what is in progress, and what compensating controls are in place.
Analyst Perspective
The AAR is your team's opportunity to justify investment. If the incident revealed that the SIEM had a 3-day log gap because storage was undersized, the AAR is where you make the case for expanding it. If the flat network enabled lateral movement in under 2 hours, the AAR quantifies the cost of not segmenting. Tie every recommendation to a specific finding from the incident. Abstract requests get ignored; evidence-backed requests get funded.
11.5 Program Improvement and Plan Maintenance
The PIR and AAR are not shelf documents. They must drive concrete changes to the organization's security posture, incident response capability, and operational procedures. This is where the IR lifecycle closes the loop: the lessons learned from this incident become the preparation (Chapter 6) for the next one.
Updating Plans and Playbooks
Every process gap identified in the PIR should result in a specific update:
- IR Plan (Chapter 6): Revise escalation criteria, update call trees, adjust severity matrix thresholds if the escalation triggers were inaccurate during this incident.
- Playbooks: Update or create playbooks for the specific attack type encountered. If the organization did not have a "Credential Theft with Lateral Movement" playbook, build one based on the Meridian scenario.
- BIA (Chapter 2): If the incident revealed dependency mismatches (a Tier 2 system that could not function without a Tier 3 system that was deprioritized during recovery), update the dependency maps and criticality assignments.
- Crisis Communication Plan (Chapter 4): If the external communications were delayed, unclear, or inconsistent, revise the holding statements and notification workflows.
Updating Detection Rules
The attacker's TTPs, mapped to MITRE ATT&CK during Analysis (Chapter 8), should be translated into permanent detection improvements:
- New SIEM correlation rules that would have detected this specific attack pattern earlier.
- New or tuned EDR detection rules for the persistence mechanisms encountered (the rogue GPO, the malicious scheduled tasks).
- Updated threat intelligence feeds with the IOCs from this incident (C2 domains, file hashes, attacker infrastructure IPs).
- Validation that these new detections actually fire. Schedule a test using the known attack artifacts.
Exercise Backlog
Improvements are only real if they are tested. Every recommendation from the PIR should be validated through exercises:
- Tabletop exercise replaying the incident scenario against the updated plans to confirm the gaps are closed.
- Technical drill testing the new detection rules: do they fire when the attacker's known TTPs are simulated?
- Recovery drill validating that the updated BIA priorities and dependency maps produce the correct restoration sequence.
Track every improvement item to closure. An open recommendation from a PIR that is never implemented is worse than not having the PIR at all, because it means the organization identified the problem, acknowledged the risk, and chose to do nothing.
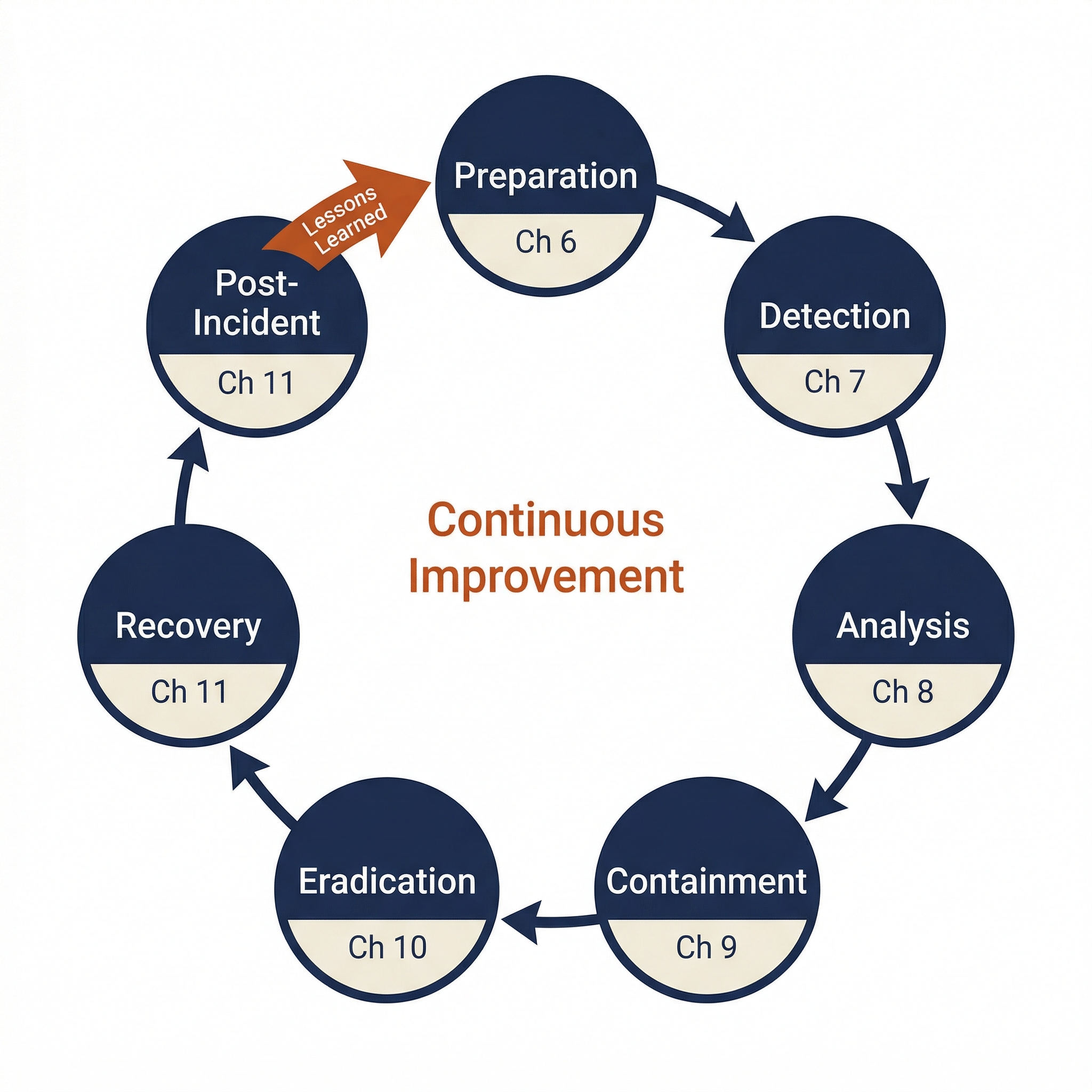
Closing the Loop
This section is the structural payoff for the entire IR lifecycle. Chapter 5 introduced the seven-phase lifecycle as a circle, not a line. Chapter 11 is where that circle completes:
- The lessons learned from this incident update the Preparation (Chapter 6) for the next one.
- The detection gaps revealed during this incident create new Detection rules (Chapter 7).
- The analysis challenges encountered feed into improved Analysis procedures (Chapter 8).
- The containment decisions are reviewed and refined for future Containment playbooks (Chapter 9).
- The eradication and remediation tracking continues until every item is closed (Chapter 10).
The IR lifecycle does not end. It resets, and the organization is stronger for having completed it.
Putting It Together: Recovery at Meridian Financial Services
The Meridian Financial CSIRT has completed eradication and verification. The Incident Commander authorizes the transition to Recovery.
Phased Recovery Execution
The team restores systems according to BIA priority, respecting dependency chains:
| Recovery Wave | Systems | Dependency Gate | Validation |
|---|---|---|---|
| Wave 1 (Day 5, Hour 0) | DC-01, DC-03 (already clean), DNS/DHCP | None (foundation tier) | AD replication healthy; DNS resolving correctly |
| Wave 2 (Day 5, Hour 4) | DC-02 (rebuilt in Ch 10), Email server | AD online, DNS functional | Authentication working; mail flow confirmed |
| Wave 3 (Day 6) | FS-HR-01 (reimaged), Finance reporting app | AD online, network segmentation rules active | HR validates employee PII data intact; Finance confirms quarterly reporting functional |
| Wave 4 (Day 7) | WS-FIN-042, WS-MKTG-019, 12 GPO-affected workstations (all reimaged) | AD online, EDR deployed, segmentation active | Users confirm access to applications; no anomalous activity in 48-hour monitoring window |
Recovery Acceptance
After a 48-hour enhanced monitoring window, the SOC confirms:
- No C2 beacon attempts detected from any recovered system (sinkhole logs clean).
- No unauthorized authentication events or process execution anomalies.
- All EDR agents reporting current telemetry. All log sources flowing to SIEM.
The HR Director confirms that all 2,000 employee records are present and the PII data matches pre-incident records. The Finance Director confirms the quarterly reporting application is producing accurate results. Both sign the recovery acceptance form.
Post-Incident Review (10 Days After Closure)
The PIR convenes with the full response team. Key findings:
- What went well: The DNS sinkhole containment technique identified a fourth compromised host (WS-MKTG-019) that Analysis had missed. The coordinated lockout prevented data exfiltration. The KRBTGT double-reset was executed correctly.
- What could be improved: The 72-hour MTTD indicates that the C2 beaconing pattern should have been detected sooner. The flat network allowed the attacker to move from a Finance workstation to a Domain Controller in under 3 hours. The
svc-backupservice account had not been reviewed in 14 months. - Action items: 8 recommendations generated, 5 of which are already tracked in the remediation plan from Chapter 10. Three new items added: implement scheduled service account reviews (quarterly), create a "Credential Theft with Lateral Movement" playbook, and deploy a SIEM correlation rule for Kerberos anomalies.
Metrics for the AAR:
- MTTD: 72 hours
- MTTR: 8 hours
- Dwell Time: ~5 days
- Time to Recover: ~2 days
- Total Incident Duration: 7 days (Day 0 compromise to Day 7 full recovery)
Chapter Summary
Recovery and Post-Incident Activity are the final phases of the IR lifecycle, but they are not the end of the story. Recovery restores operations; Post-Incident Activity ensures the organization emerges stronger.
-
Recovery is phased and prioritized based on the BIA criticality tiers (Chapter 2). Tier 1 Mission-Critical systems come first, followed by Tier 2 through Tier 4 in sequence. Dependency chains determine the exact order within each tier.
-
Hardening before reconnect is mandatory. Systems rebuilt during eradication must pass security control validation checks before being returned to the production network.
-
Recovery is a high-risk window. Enhanced monitoring must run on every recovered system. Any sign of residual compromise halts recovery on that system and loops back to Analysis.
-
Recovery acceptance requires dual sign-off. The technical team confirms system health and security controls, and the business owner confirms data accuracy and application functionality.
-
Data integrity validation operates on two levels: technical (hash checks, database consistency) and business (end-user verification of restored records). In ransomware recovery, backup age and completeness must be communicated honestly.
-
The Post-Incident Review (PIR) is conducted within 1-2 weeks of closure using blameless methodology. It focuses on process failures, not individual failures, and produces specific action items with owners and due dates.
-
IR metrics (MTTD, MTTR, dwell time) transform subjective narratives into objective measurements. They reveal where the program is strong and where investment is needed.
-
The After Action Report (AAR) translates the incident into business risk language for executive leadership. It is the vehicle for justifying security investment based on evidence, not opinion.
-
Program improvement closes the loop. Updated plans, new detection rules, revised playbooks, and scheduled exercises ensure that the lessons from this incident become the preparation for the next one. The IR lifecycle is circular, and the organization is stronger for completing it.
In the next chapter, we apply the complete IR lifecycle to the most prevalent threat in the field today, Ransomware, building a detailed playbook from initial detection through clean recovery.